Designing High-Throughput Systems: Tradeoffs, Patterns, and Practical Lessons
In a previous system I worked on, I needed to run internal database migrations across thousands of user-specific databases. Each user had their own database—a design choice that provided strong isolation, but introduced significant operational complexity when it came time to keep schemas in sync.
To solve this, I built a Python Flask API with a single endpoint responsible for orchestrating migrations. Instead of issuing a request per database, the API would accept a migration command, retrieve all tenant database identifiers from MongoDB or DynamoDB (depending on the environment), and coordinate the migration process across them.
The problem was that the system was entirely synchronous.
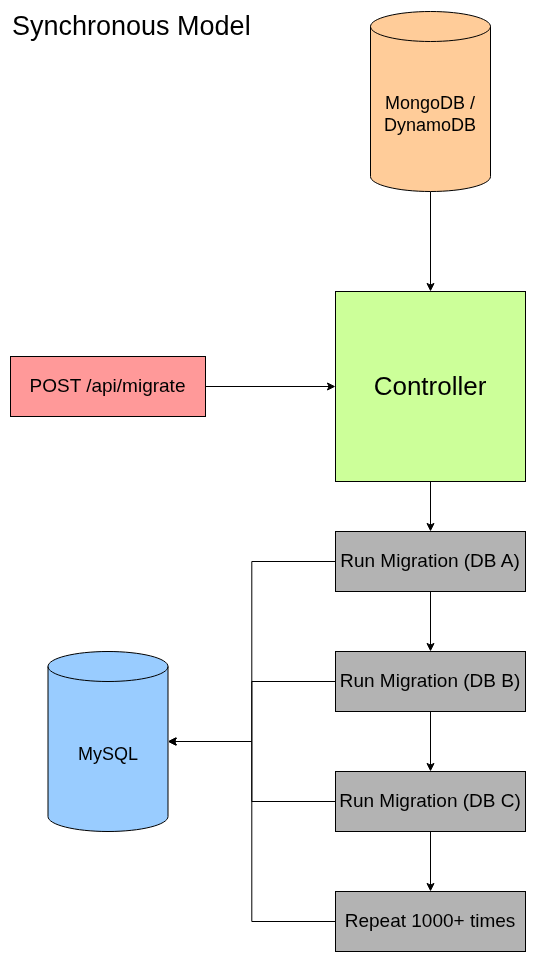
Synchronous Model
Even though orchestration was centralized, migrations were still executed one database at a time—like standing in line for a roller coaster where only one person is allowed to ride. As the number of databases grew, so did the total execution time. In some cases, migrations had to run overnight just to complete.
At that point, the problem was no longer correctness—it was throughput.
One of the reasons Python was chosen for this system was its support for multithreading, with the expectation that migration execution could be parallelized across many databases. My first instinct was to lean into that by spawning threads within the controller so that multiple migrations could run concurrently.
However, no matter how much I increased the number of threads, it didn’t meaningfully improve overall performance.
The issue wasn’t that threading was ineffective—it was that concurrency was introduced at the wrong layer. The entire migration process was still tied to a single request lifecycle, with no mechanism to distribute work across independent execution units.
In other words, I was scaling threads, but not scaling the system.
Solving that problem required more than just making the system faster. It required rethinking how the work itself was structured.
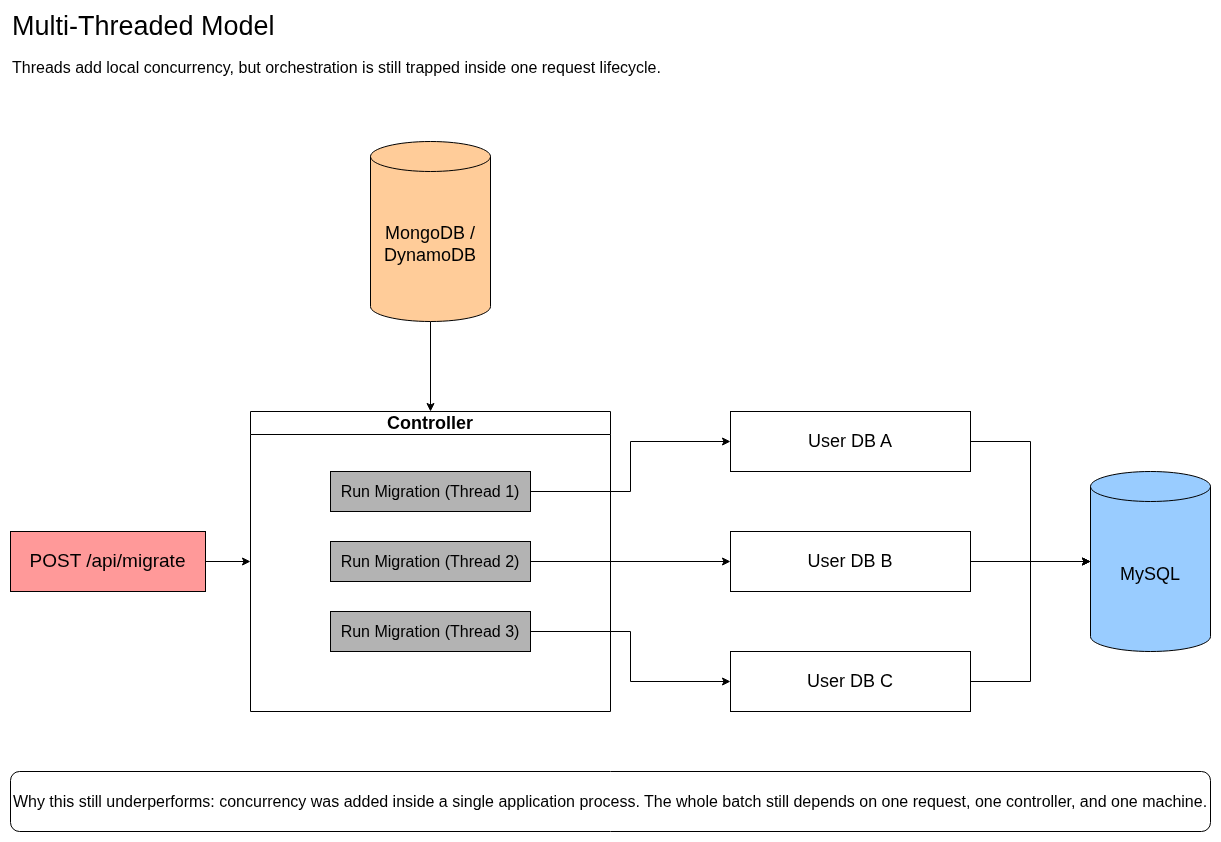
Multi-Threaded Model
High-throughput Design Principles
1. Identify the Bottleneck
The most important lesson I learned from this experience is that throwing technology at a slow system is not the same as designing for throughput. I knew from the beginning that a fully synchronous migration process would not scale, which is why I initially reached for Python’s multithreading capabilities. The instinct wasn’t wrong—but the execution was.
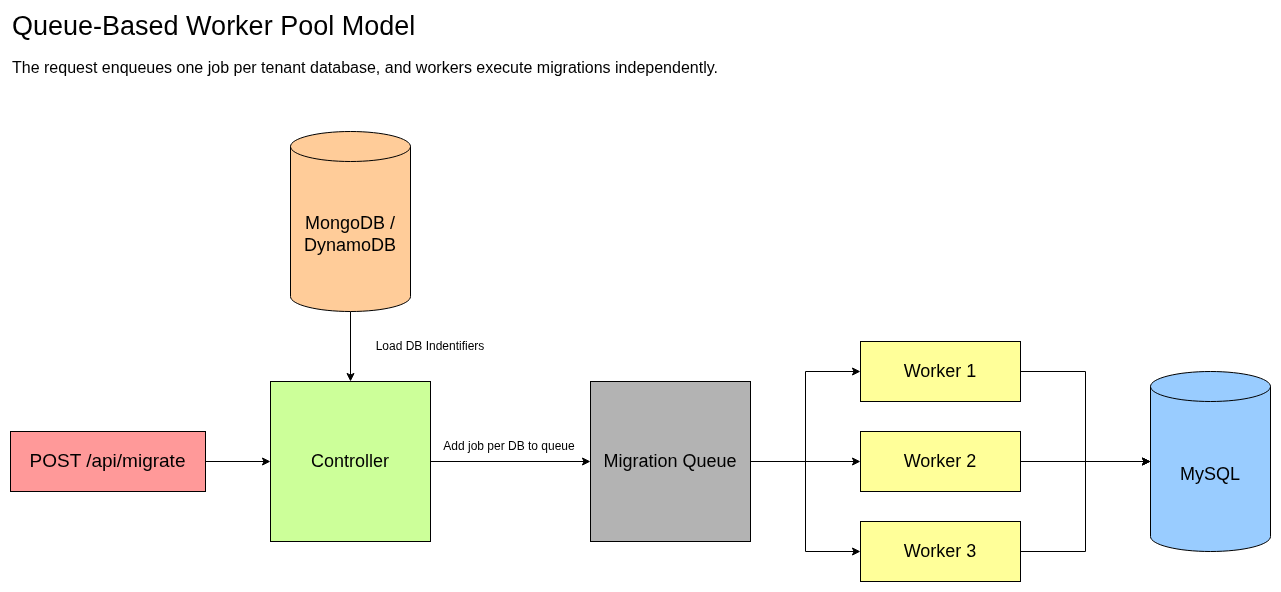
Even after introducing a queue and reducing migration time from hours to minutes, I realized I had still been guessing. I was asking, “What tool can I use to make this faster?” instead of asking the more important question: “Where is the system actually spending its time?”
This is where observability becomes critical. Without measurements, throughput tuning is little more than trial and error. What matters is understanding whether the system is actively doing work or simply waiting.
At a minimum, I want visibility into things like request and job duration, queue depth, database query latency, connection usage, and error rates. These signals help answer a simple but fundamental question: Is the system slow because it is working, or because it is waiting?
2. Classify the Bottleneck
Once you understand where time is being spent, the next step is to classify the type of bottleneck. Not all performance issues are the same, and applying the wrong solution can make things worse instead of better.
A system may be CPU-bound, meaning it is spending most of its time performing computation. This often shows up in heavy data transformations, serialization, or expensive business logic. In these cases, the solution is usually to make the work itself cheaper—optimize algorithms, reduce unnecessary computation, or scale compute resources.
Other systems are I/O-bound, where the majority of time is spent waiting on external systems such as databases, filesystems, or APIs. This is where concurrency becomes effective. By overlapping waiting time, the system can make progress on multiple tasks simultaneously. However, increasing concurrency without limits can overload downstream systems, so it must be applied carefully.
Contention-bound systems are a different kind of problem. Here, multiple workers are competing for the same shared resources—database locks, connections, or disk access. In these cases, adding more parallelism can actually reduce throughput. The solution is often to reduce contention by shortening transactions, redesigning access patterns, or limiting concurrency to a sustainable level.
Some systems are not limited by computation or I/O, but by coordination. Too much work is tightly coupled or executed sequentially when it does not need to be. This was the core issue in my migration system. Decoupling work—typically through queues or event-driven patterns—can unlock significant throughput improvements by allowing independent tasks to execute in parallel.
Finally, there are external dependency bottlenecks. Sometimes the system is limited by a resource you do not control, such as a third-party API or a shared database service. In those cases, the architecture must adapt by throttling requests, batching work, or isolating those dependencies so they do not dominate the entire system.
The key insight is that each of these bottlenecks requires a different approach. There is no universal solution.
3. Choosing the Right Solution
Once the bottleneck is understood, the next step is choosing the right tool for the job. This is where many systems go wrong—not because the tools are bad, but because they are applied without a clear understanding of the problem.
Queues, for example, are extremely useful when the system is doing too much work synchronously or when execution needs to be decoupled from request handling. They help smooth bursts, distribute work, and enable retries. However, they also introduce complexity and eventual consistency, which may or may not be acceptable depending on the use case.
Worker pools are a natural extension of this model. They allow work to be processed in parallel, but only when that work is truly independent. The challenge is not just adding workers, but determining how many can safely run at once without overwhelming shared resources.
Caching is another powerful tool, particularly in read-heavy systems. By trading perfect freshness for speed, caching can significantly reduce load on downstream systems. But it also introduces new challenges, especially around invalidation and consistency.
Horizontal scaling is often seen as a universal solution, but it is only effective when the application layer is the bottleneck. If the system is constrained by a shared database or external dependency, adding more application instances simply increases pressure on the same resource.
Partitioning or sharding becomes relevant when a system can no longer scale within a single shared resource. By splitting data or workload into separate lanes, it is possible to reduce contention and scale further. However, this comes at the cost of increased complexity in routing, balancing, and operational management.
Each of these tools is valuable, but none of them are universally correct—they only make sense in the context of the constraint they are addressing.
A Practical Throughput Mindset
When designing for throughput, I try to avoid asking:
What technology should I use?
Instead, I focus on a different set of questions:
What resource is constrained?
What kind of waiting is happening?
What work is being unnecessarily serialized?
What work is too expensive per unit?
What happens if I increase concurrency here?
Where does the bottleneck move if I relieve this one?
That last question is especially important. Improving throughput in one part of the system almost always exposes the next constraint.
Every throughput optimization is also a bottleneck relocation strategy.
A Simple Decision Framework
A useful way to reason about this is:
If the system is waiting, introduce concurrency carefully
If the system is computing, optimize or add compute
If the system is contending, reduce shared pressure
If the system is too coordinated, decouple it
If the system is read-heavy, consider caching
If the system is limited by infrastructure, scale or redesign that layer
This framework is not perfect, but it is far more effective than defaulting to a favorite tool or pattern.
The Real Tradeoff in High-Throughput Design
High-throughput system design is not just about making things faster. It is about deciding what kind of complexity you are willing to introduce in order to move the bottleneck.
Queues trade simplicity for decoupling.
Caching trades freshness for speed.
Worker pools trade coordination for parallelism.
Horizontal scaling trades simplicity for distribution.
Sharding trades operational ease for capacity.
There is rarely a single “best” solution—only a set of tradeoffs that make sense given the current constraints.
Conclusion
The queue-based approach solved the immediate problem. Migrations that once took hours could now complete in minutes, and the system was no longer constrained by a strictly sequential execution model.
But the more important outcome was not the performance improvement—it was the shift in how I approached system design.
High-throughput systems are not built by defaulting to specific tools or patterns. They are built by understanding where time is being spent, what resources are constrained, and how work flows through the system. Every optimization is ultimately an attempt to relieve a bottleneck, and every improvement moves that bottleneck somewhere else.
That is why there is no single “correct” architecture for high-throughput systems. There are only tradeoffs.
Queues introduce decoupling at the cost of complexity.
Caching improves speed at the cost of freshness.
Parallelism increases throughput at the cost of coordination.
Scaling distributes load but does not eliminate shared constraints.
The goal is not to eliminate these tradeoffs, but to make them intentionally.
Looking back, the biggest mistake I made early on was focusing on the tools instead of the constraints. Once I started asking better questions—where is the system waiting, what is actually limiting throughput, and what happens if I change this part of the system—the solutions became much clearer.
Designing for throughput is less about making systems faster and more about understanding how they behave under pressure.
In high-throughput systems, performance is rarely a mystery—it’s usually a matter of asking the right questions.